Superagency
; 4 mins read
I recently completed Reid Hoffman's Superagency. It was a great book. I'll detail some interesting points worth noting below.
First, since the 1980s, US GDP per capita has risen at a rate ~1.3x that of US median income (see the graph below).
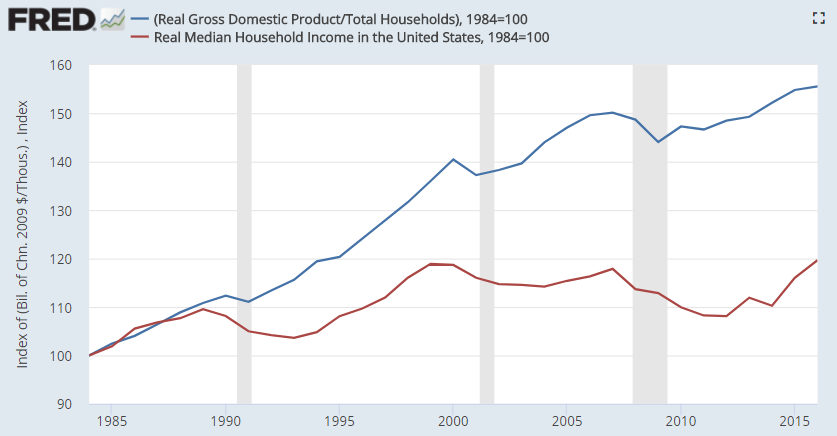
I suspect this multiple has only increased in the last decade. Despite the serious levels of technological innovation we have seen, it's so fascinating that value has implitly accrued to the top x% of society through the of electronics, media, and more. Will future waves of technology and AI gains amplify this divergence? Is there truly a way to design a system that distributes economic gains more evenly? Is it even a problem that there is such disparity?
What makes this wave of AI special is that it is a cognitive multiplier of sorts. At some point, we will see skill compression, where the gap between novice and expert closes. When workers can become skilled faster, will institutions replace workers or give them superpowers? This is really a question about institutions and firm incentives. Nevertheless, there is certainly potential for that initial gap to close, but also arguably more potential for it to widen (e.g., think about the focus many startups have on lean teams even while turning over millions in ARR).
Second, we should think about the consumer surplus generated by OAI and other providers. Erik Brynjolfsson (Stanford) and Avinash Collis (CMU) conducted experiments to proxy the consumer surplus generated by Facebook by offering various amounts of money to a sample of Facebook users to give up Facebook for one month. The median compensation for price-to-sacrifice was $48/m. For search engines, this was $1,461/m. For email, this was $701/m. And for digital maps, this was $304/m. The internet generates huge amounts of surplus – as ChatGPT, etc. become more entrenched in our day-to-day style of working, surely our PTS would only grow. But what would this number be now? I would answer with $500/m to void all LLM usage – this includes the Gemini feature in Google preview. LLMs are an integral part of how I work/navigate/search for things.
Third, how have I never previously heard of Chatbot Arena? Wow, love it. I tested it out (now called LMArena) and was surprised that Stability's Beluga model (I think v2) explained how LLMs work far better than Claude (blanking on the model).
Fourth, permissionless innovation vs precautionary principle has been an underlying, back-and-forth issue for as long as innovation has been a thing. From the industrial revolution to the internet age, society has oscillated between allowing new tech to emerge freely and restricting them until risks were fully anticipated/addressed. Hoffman explains that the precautionary approach leads to assymetric incentives. It overweighs visible, short-term harms and underweighs long-term benefits, ultimately delaying what may have far earlier provided value to society. You could almost argue there are ethical costs to excessive caution.
I believe that as AI adds more leverage to the human skillset, falling into this trap of unnecessary conservatism will only increase its cost (opportunity cost). Especially as certain regulation may block forms of experimentation, we extend the time it takes to build on "human agency," as Hoffman puts it.
Fifth, as the distribution for intelligence/skills, albeit AI-assisted, becomes more uniform relative to at present, what attribute becomes the most important to evaluate ourselves on? This is a standing question.
Finally, the "latent expertise" of LLMs (as per Wharton's Ethan Mollick), should not be taken for granted. This is all of the knowledge an LLM has learned through the process of training. Its this feature that makes it particularly compelling for LLMs to be used by experts, who can ask prompts best implictly designed to cultivate latent expertise.